

The world of data science is constantly evolving, and as we step into 2023, we find ourselves at the forefront of exciting advancements and groundbreaking innovations. Data has become the lifeblood of modern organizations, fueling insights, driving decision-making, and transforming industries. In this blog post, we will explore the latest trends and developments in data science that are shaping the landscape in 2023 and beyond.
1. Augmented Analytics:
Augmented analytics leverages artificial intelligence and machine learning algorithms to enhance the capabilities of data scientists and empower citizen data scientists. With automated data preparation, smart data discovery, and natural language processing, augmented analytics platforms enable users of varying technical backgrounds to explore and derive insights from complex datasets. This democratization of data science fuels innovation by fostering a data-driven culture throughout organizations.
- Smart Data Discovery for Enhanced Insights: Augmented analytics platforms are equipped with smart data discovery capabilities that enable users to uncover patterns, trends, and relationships within their datasets. These platforms use machine learning algorithms to identify correlations, outliers, and anomalies, providing users with valuable insights that may have gone unnoticed otherwise.
- Natural Language Processing for Intuitive Interaction: By incorporating NLP capabilities, these platforms allow users to interact with data using natural language queries. This intuitive interface makes data exploration and analysis accessible to users who may not have programming or SQL skills.
- Democratizing Data Science: One of the key strengths of augmented analytics is its ability to democratize data science. Individuals from various departments and backgrounds can actively contribute to data exploration, uncovering insights that can lead to innovation, process optimization, and improved decision-making across the board.
- Fostering Innovation and Growth: By enabling more individuals to engage with data and derive insights, organizations can uncover hidden opportunities, identify customer preferences, and respond quickly to market changes.
2. Deep Learning and Neural Networks
Deep learning, a subset of machine learning, continues to make waves in the data science landscape. Neural networks are being utilized to tackle complex problems such as image recognition, natural language understanding, and speech synthesis. With the ability to process large volumes of data, neural networks are unlocking new possibilities for pattern recognition, predictive modeling, and decision-making.
- Unleashing the Potential of Deep Learning: Deep learning, a subset of machine learning, focuses on training artificial neural networks with multiple layers to process and extract meaningful representations from data. This combination allows deep learning models to learn complex patterns and relationships, enabling them to outperform traditional machine learning techniques in various domains.
- Advancements in Neural Network Architectures: Convolutional Neural Networks (CNNs) have revolutionized image recognition tasks by learning hierarchical representations and detecting features at different levels. Recurrent Neural Networks (RNNs) excel in natural language understanding and speech synthesis, capturing the temporal dependencies in sequential data.
- Applications in Image Recognition: Deep learning and neural networks have made significant strides in image recognition tasks. These models can learn intricate visual patterns and automatically extract relevant features from images, enabling applications such as autonomous vehicles, medical imaging analysis, and content-based image retrieval.
- Enhancing Natural Language Understanding: The power of deep learning and neural networks is also evident in natural language understanding tasks. RNNs and Transformer-based architectures have revolutionized machine translation, sentiment analysis, chatbots, and question-answering systems.
- Predictive Modeling and Decision-making: Deep learning has made a significant impact on predictive modeling and decision-making. By leveraging neural networks, organizations can build models that can process and analyze vast volumes of data to generate accurate predictions and make informed decisions. Deep learning models have been successful in various domains, including finance, healthcare, marketing, and supply chain management.
3. Federated Learning: Collaborative Intelligence
Federated learning has emerged as a game-changer in the era of privacy-conscious data science. This decentralized approach allows multiple parties to collaborate on model training without sharing their raw data. By enabling organizations to pool their knowledge and resources while preserving data privacy, federated learning fosters collaborative intelligence and facilitates the development of robust, generalized models.
- Preserving Data Privacy: Traditional machine learning approaches often require centralized data aggregation, which raises concerns about data security and privacy breaches. By training models locally and exchanging only encrypted model updates, federated learning ensures that sensitive data never leaves its source, thereby mitigating privacy risks and complying with data protection regulations.
- Collaborative Model Training: In federated learning, organizations collaborate to train models collectively while keeping their data secure. Each organization trains the model using its local data and shares encrypted model updates with a central server. These updates are then aggregated to create a global model that benefits from the collective knowledge and diverse datasets of all participants.
- Enabling Cross-Industry Collaboration: In healthcare, for instance, federated learning allows hospitals and research institutions to collaborate on training models for disease diagnosis while respecting patient privacy. Similarly, in finance and telecommunications, federated learning facilitates the analysis of large-scale data while preserving the confidentiality of sensitive customer information.
- Overcoming Data Silos: Traditionally, organizations keep their data isolated, limiting the insights that can be derived from collective intelligence. With federated learning, organizations can pool their knowledge and resources without exposing their proprietary data, leading to more comprehensive and accurate models.
- Advancing AI in Edge Computing: Federated learning is a natural fit for edge computing as it allows devices to participate in model training while maintaining data privacy. This decentralized approach reduces the reliance on high-bandwidth connections and minimizes latency, making federated learning an efficient solution for AI applications at the edge.
4. Automated Feature Engineering and Explainable AI
Automated feature engineering tools leverage machine learning algorithms to generate and select relevant features from raw data, reducing the manual effort and time required. Additionally, explainable AI techniques are gaining prominence, enabling data scientists to understand and interpret the decision-making process of complex models.
- The Power of Efficiency: Leveraging machine learning algorithms, these tools automatically identify, generate, and select features based on their relevance to the problem at hand. By automating this crucial step, data scientists can save time and effort, allowing them to focus on higher-level analysis and problem-solving.
- Explainable AI: By using methods such as feature importance analysis, partial dependence plots, and rule extraction, data scientists can gain a deeper understanding of the model’s inner workings. This transparency not only facilitates trust and acceptance of AI models but also enables data scientists to identify and rectify potential biases or flaws in the decision-making process.
- The Synergy of Automated Feature Engineering and Explainable AI: Automated feature engineering and explainable AI techniques complement each other, creating a powerful synergy within the data science workflow. Automated feature engineering lays the foundation by efficiently extracting relevant features from raw data, while explainable AI techniques provide insights into how these features contribute to the model’s predictions.
5. DataOps and MLOps:
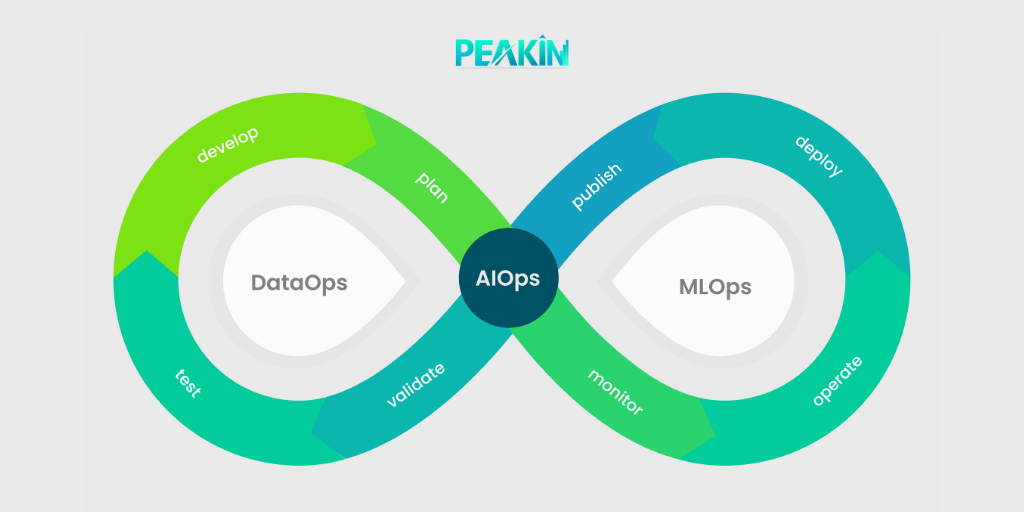
DataOps focuses on the collaboration and integration of data teams, breaking down silos and optimizing data pipelines. MLOps, on the other hand, addresses the operationalization and management of machine learning models, ensuring smooth deployment, monitoring, and iteration. By adopting DataOps and MLOps practices, organizations can accelerate their time-to-value, improve model performance, and foster a culture of continuous learning and improvement.
- DataOps:. By embracing DataOps, organizations can establish standardized processes and tools for data integration, data governance, and data quality assurance. This streamlines the data preparation and transformation steps, enabling data scientists to spend more time on analysis and modeling.
- MLOps: Operationalizing and Managing ML Models: MLOps addresses challenges such as model version control, reproducibility, scalability, and performance monitoring. By implementing robust monitoring and feedback mechanisms, organizations can gather insights on model performance, identify and address issues promptly, and enhance the overall effectiveness of their machine learning initiatives.
- The Synergy of DataOps and MLOps:.With DataOps and MLOps, organizations can establish best practices for version control, reproducibility, and scalability, facilitating easier collaboration and knowledge sharing among data teams. The iterative nature of MLOps enables organizations to adapt models to evolving data and business requirements, ensuring the ongoing effectiveness of their machine learning initiatives.
6. Quantum Computing:
With the potential to solve complex optimization problems, accelerate data analysis, and enhance machine learning, quantum computing offers a glimpse into a future where data science reaches new heights. As quantum technologies continue to advance, the impact on data science will become more pronounced, enabling us to unravel the mysteries of vast datasets and unlock new insights that were once beyond reach.
- Quantum Algorithms for Complex Optimization: Traditional computers struggle with optimization tasks that involve searching through vast solution spaces. By leveraging quantum principles like superposition and entanglement, quantum algorithms have the potential to provide faster and more efficient solutions to optimization problems, revolutionizing fields such as supply chain optimization, portfolio management, and scheduling.
- Challenges and Future Outlook: While quantum computing holds immense promise for data science, there are significant challenges to overcome. Quantum systems are highly sensitive to noise, making error correction and reducing decoherence crucial for practical quantum computing. Additionally, the development of large-scale, fault-tolerant quantum computers is still ongoing.
Conclusion:
Augmented analytics, deep learning, federated learning, automated feature engineering, explainable AI, DataOps, MLOps, and the potential of quantum computing are driving the evolution of data science. Embracing these trends and harnessing their power will enable organizations to unlock the full potential of their data, make informed decisions, and stay ahead in a data-driven world. The future of data science is here, and it’s an exciting journey into uncharted territories of knowledge and innovation.